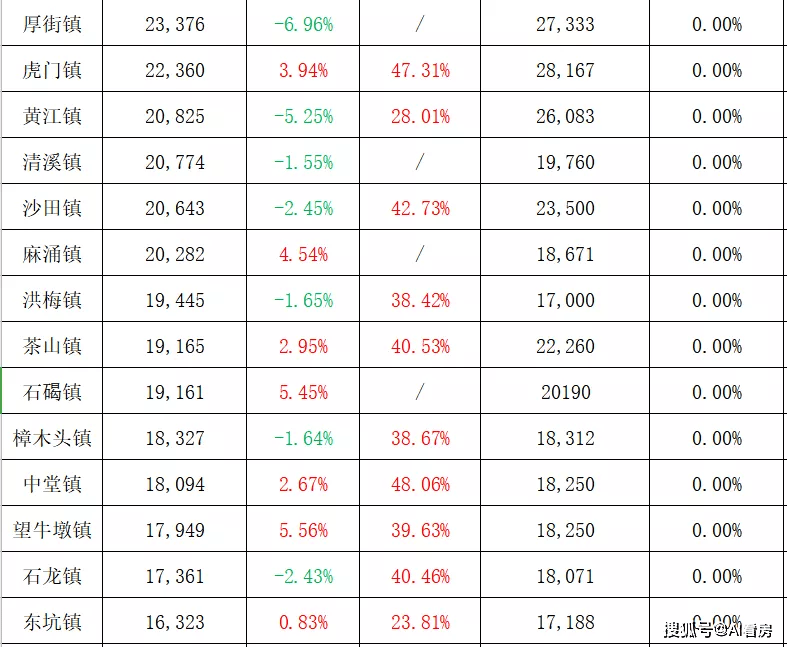
引言
标题:“管家婆必出一肖一码一中,数据分析计划_机器版54.298”
分析的数据类型
机器版54.298的管家婆必出一肖一码一中计划中,主要涉及三种类型的数据:金融类、社会类和个人信息类。
金融类数据
金融类数据涉及管家公金库、银行存款、各个金融产品的保值增值等多个子项。
社会类数据
社会类数据涉及国家政策、产业发展趋势、人口基础等多个维度。
个人信息类数据
个人信息类数据要求管家婆必须掌握家庭成员的身体健康、工作状态、收支情况等。
设置数据的优先级
针对不同类别的数据,管家婆可以通过优化算法来进行优先级别的划分,您可以使用机器学习的技术,通过对数据重要性的识别,来自动判断数据的优先级。
数据的质量评估
对于机器来说,数据质量的好坏将直接影响到方案的可行性。因此,管家婆需要对于各类数据进行质量评估。数据质量评估又可以从以下几个方面进行考虑:真实性、一致性、完整性、时效性。
数据的清洗处理
管家婆需要对于数据进行去噪处理、缺失值填补、异常值剔除等处理过程。
如何利用法律手段保护个人隐私
在利用个人信息的时候,能够保证数据主体的隐私安全是非常重要的。管家婆需要清楚地了解《个人信息保护法》,对于数据的存储、传输、使用等各个环节都要做到合法合规。
数据星链
管家婆需要构建一条数据星链,将家庭的各类数据进行汇总比对。“星链计划”的名字,源于spaceX的星链计划,意味着打造一张布网全球的信息网,点对点的信息传输可以不受地理因素限制。
设计并实现数据的安全流通机制
管家婆必出一肖一码一中计划关键在于多计算中心、多应用场景的数据安全流通机制的构建,需要在人工智能学习、云计算等领域曼进行深入研究与实践。管家婆需要对各个环节的信息进行全链路的安全保护,包括数据传输与存储,以及数据流转与应用,加密技术是必不可少的手段。
机器学习算法与模型
管家婆需要根据不同的应用场景设计不同的机器学习算法,并训练相应的模型。机器学习目前主要有三种流派:以统计学理论为基础的传统机器学习,以神经网络为核心的深度学习,以及与传统计算方法结合产生的群体智能方向。管家婆需要基于海量数据来进行复杂的计算,并从中找出规律,对于模型的准确性要达到可靠的程度。
基于决策树模型实现复杂逻辑计算
机器学习中的决策树模型可以理解为把已有的数据经验化的方法来解决分类和回归问题。决策树模型适用于管家婆需要将各种数据经验综合在一起的场景,比如金融决策分析:生存分析、收益率预测、违约风险度量、资产交易信号识别等复杂的处理任务. demos为管家婆的例子-模型,就以决策树来模拟了如下步骤:
数据输入与处理
1.输入POS机每日流水记录 2.输入每日租赁信息 3.输入子公司分公司每日生产量等数据电梯 综合输入各子项数据,处理各类缺失值、一致性校验等任务
分类器的构建
1. 计算数据特征对应的熵 2. 计算熵增 3. 选择最佳特征进行划分 4. 损失函数的选择 5. 划分数据 6. 递归以上步骤,直至构建完成整棵树
训练与测试
1. 通过交叉验证方法进行准确率预测 2. 以_POC调查有效性
最终决策
1. 模型输出将指导具体业务处理 2. 根据模型提供预测结果进行优化调整
基于强化学习算法的动态配置
强化学习提供了一种可行的优化途径:自我摸索目标和策略的序列决策过程。管家婆基于ABC公司既有的知识背景,并未积累像BAT等公司的生成数据,可以通过强化学习算法,计算出一个适应性强、可动态调整的管家婆配置,将个人数据整合成为线下可用的最终结果。example强化学习配置如下: 1. 设置策略找到最优路径 2. 将任务分布到路径的各个维度 3. 完成概率、过程、结果的评估 4. 将训练结果反作用于路径的优化
研究机器学习中的异构性
不同的数据会因为其内在结构的差异,而呈现出异构性;即使相同的数据类型在不同数据源头也会因为格式差异表现异构性。异构性的数据会对机器学习造成不小的难题,会在数据预处理环节进行去噪处理,但这个环节使得异构性的问题有解。目前异构性问题的主流技术路线是利用开源框架适配各个数据维度,并采取特征提取的方法增加算法的鲁棒性。管家婆在面对异构性问题时,需要根据数据特性分别采取不同的处理方法,比如对于表格数据可以采取公式变换的方法、对于多模态数据可以利用随机投影算法进行变换。
总结
“管家婆必出一肖一码一中,数据分析计划_机器版54.298”是一套需要管家婆借助机器学习算法、区块链以及强化学习等多种技术构建的综合型分析工具。旨在构建出一个基于对海量数据汇总处理得出优质分析结果的程序算法,能够帮助家庭主妇们从数据中发掘价值,做出最准确的生活决策。